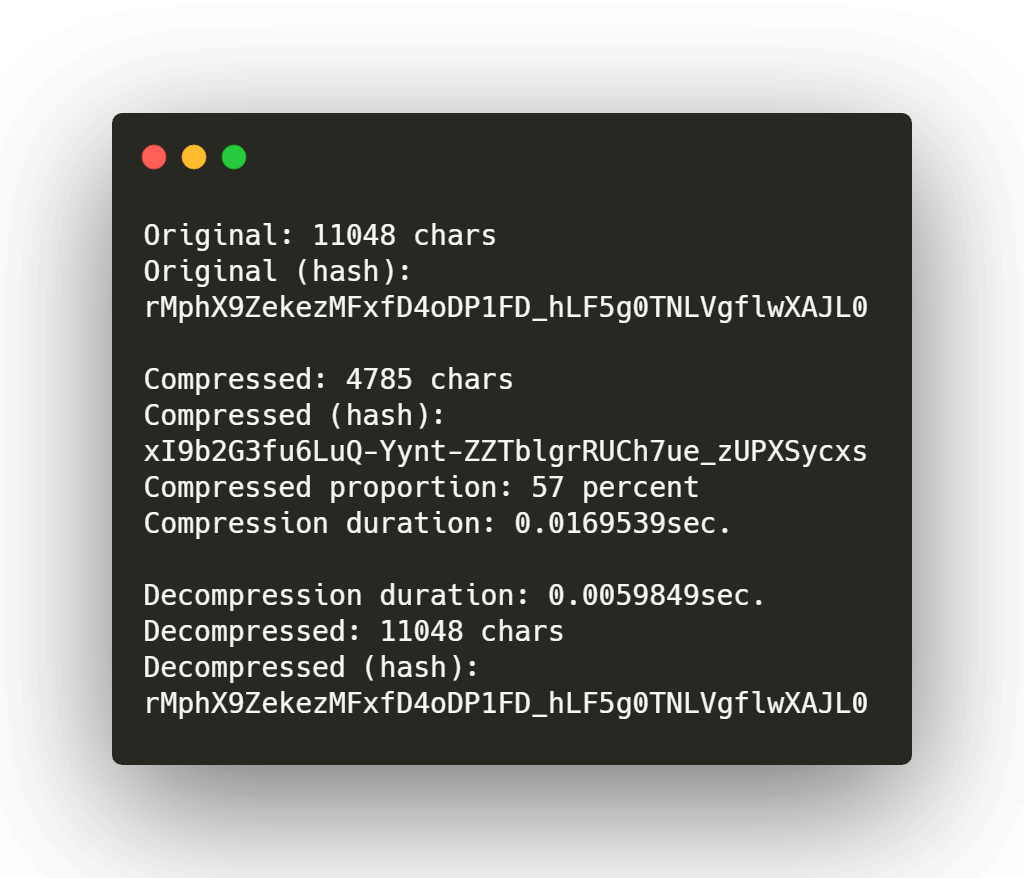
Compresión LZ77 | LZ77 Compression Algorithm
Después de muchos intentos y fracasos, y dos días de trabajo; vamos a jugar a la compresión…
La compresión es un método que nos ayuda a reducir el tamaño que requiere almacenar cierta información, haciendo uso de diferentes técnicas que pueden, o no, degradar la información procesada; permitiendo recuperar los datos suficientes para que esta sea funcional para nosotros.
En el caso de las imágenes, el audio o el video, por ejemplo, no es necesario recuperar el 100% de la información para entender el contenido de esta; de la misma manera que una línea telefónica degrada el sonido para que este sea manejable y requiera menor tiempo de transmisión y ancho de banda, pudiendo incrementar la capacidad de servicio.
Los dinosaurios recordaremos la calidad de las transmisiones de las estaciones de radio por Internet hace algunos años A.YT. (Antes de YouTube), o aquellos primeros streammings por RealPlayer que a ratos parecía rompecabezas y uno casi tenía que imaginarse 5 de cada 10 FPS, o el plug-in o reproductor que debíamos instalar para que los archivos MP3-Pro no se escucharan “tan mal”, dentro de lo posible…
Por otro lado, tenemos formatos como TIF que soportan compresión sin pérdida, es decir, que tenemos la seguridad de almacenar una imagen de alta calidad en un espacio menor al que ocupa la información de cada píxel que la compone, siendo posible reconstruirla hasta obtener esta imagen original, o por lo menos una copia fiel de esta. El herramientas como WinZip, WinRar o 7Zip, por mencionar algunas, que son capaces de almacenar varios archivos dentro de uno mismo que ocupa menos espacio que la suma del espacio necesario para almacenar cada uno; y que en algunos casos hasta es capaz de seccionar el archivo de salida en archivos más pequeños, pudiendo reconstruir la estructura completa de archivos, directorios y contenidos almacenados originalmente.
En este caso trataremos con un algoritmo sin pérdidas, uno de los primeros que sirvió de influencia para otros más sofisticados.
En este algoritmo el codificador analiza el texto como una secuencia de caracteres, mediante una ventana deslizable compuesta por dos partes; un buffer de anticipación que es la opción que está a punto de ser codificada y un buffer de búsqueda (la ventana en sí). https://www.ecured.cu/Lz77#Funcionamiento
Funcionamiento
- El algoritmo recorre el texto de manera progresiva, buscando cada vez coincidencias hacia atrás, pudiendo volver n caracteres definidos por el tamaño de la ventana.
- Si dentro de este rango se llega al inicio del texto o no se encuentran coincidencias lo suficientemente grandes, se almacena el valor del caracter actual y se avanza una posición repitiendo el ciclo.
- Si existiera una coincidencia, se almacena la posición y se evalúan los caracteres subsecuentes de la cadena y de la posición de la primer coincidencia
- Si el tamaño de la coincidencia fuera mayor al tamaño requerido para almacenar un bloque (en este caso 5 caracteres), se crea un nuevo bloque y se almacena dentro de el la cantidad de caracteres hacia atrás dela posición actual en donde encontraremos la coincidencia de los primeros caracteres y la cantidad de caracteres que coinciden y deberemos copiar para concatenarlos a la salida y reconstruir el texto.
- Reemplazamos el texto en el buffer de salida por el bloque y nos desplazamos hacia adelante la cantidad de caracteres comprimidos.
- Si hemos llegado al final del texto, habremos concluido el proceso de compresión.
Ejemplo con dibujitos…
Vamos a comprimir el siguiente texto utilizando LZ77, nuestro caracter para marcar el inicio de cada bloque será: | y cada bloque almacenará dos valores de 00 a FF, uno para definir el tamaño del desplazamiento y otro para definir el tamaño de la coincidencia por lo que cada bloque ocupará 5 caracteres de espacio; es importante remarcar que este no es el método más óptimo pues ocuparemos 2 caracteres para representar cada valor pudiendo utilizar solo un byte para cada valor, otra punto en contra es que el indicador de inicio de bloque debería ser un bit a modo de bandera para identificar si los bits siguientes son parte de un bloque o si es información sin comprimir.
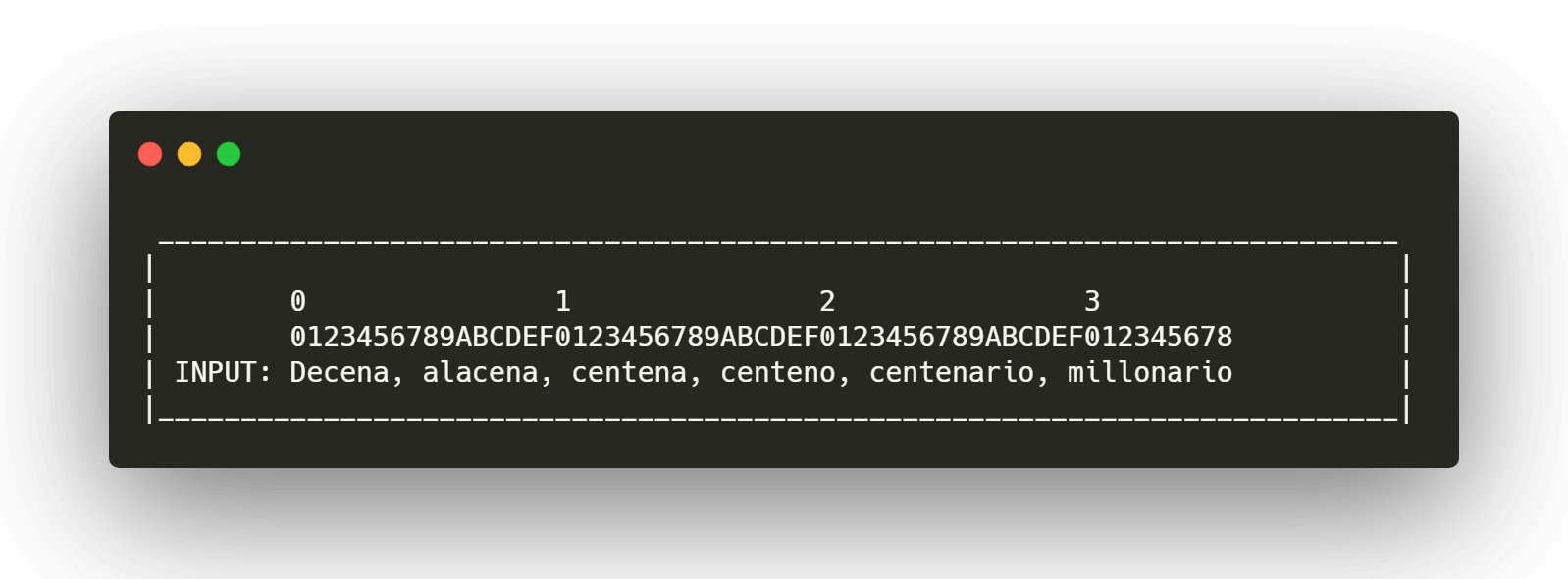
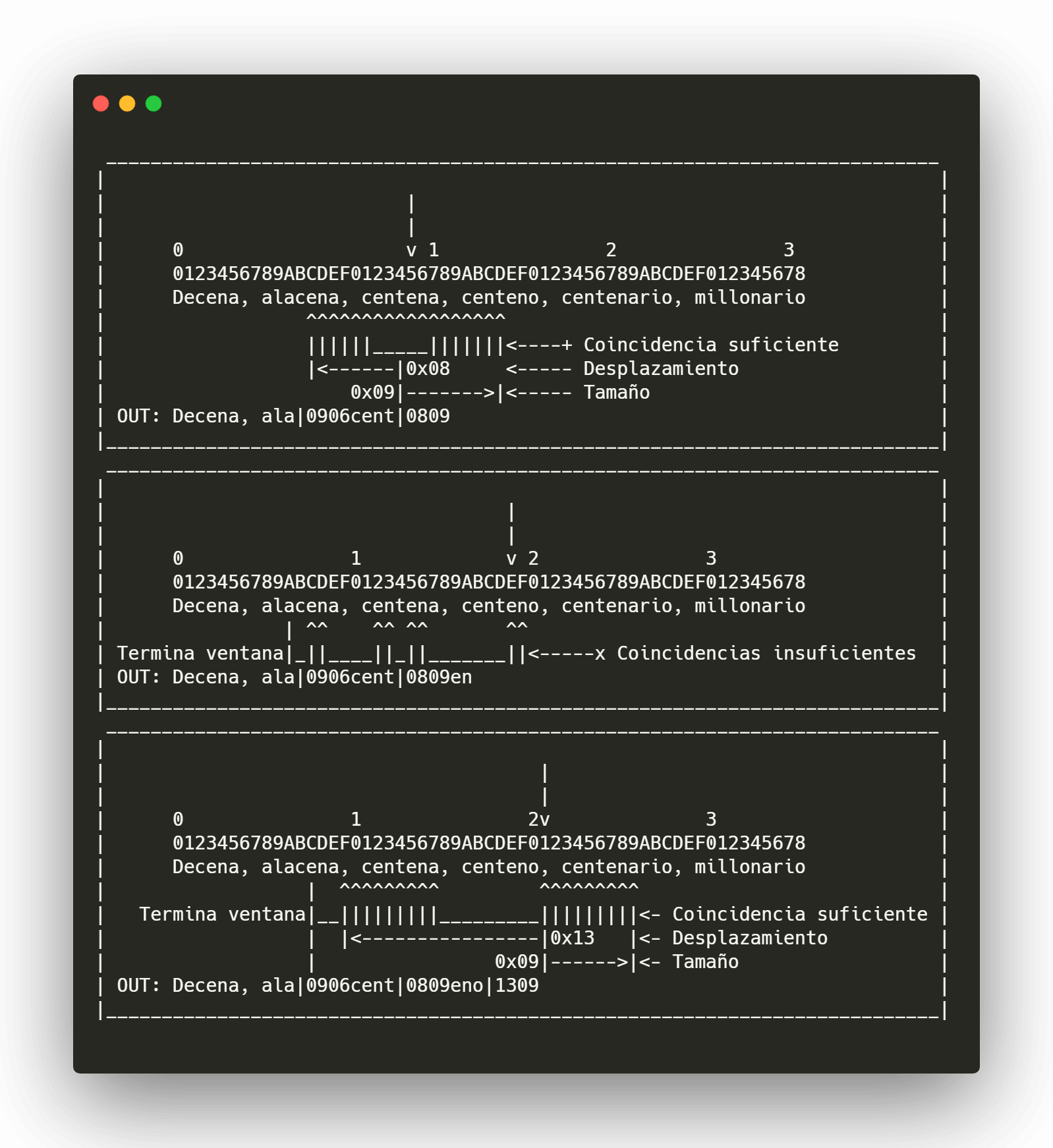
Paso 1
llenamos el buffer de salida con los caracteres originales hasta encontrar una coincidencia de tamaño suficiente para ser comprimido que se encuentre dentro de la ventana, que en este caso será de 20 posiciones a modo de ejemplo, aunque podríamos contar con valores del 0x00 al 0xFF una vez encontrada la coincidencia, agregamos el caracter | seguido del valor exadecimal del desplazamiento y el valor exadecimal del tamaño de la coincidencia, esta información le indicará al descompresor desde donde deberá comenzar a copiar caracteres del buffer de salida y la cantidad o longitud de la cadena a copiar.
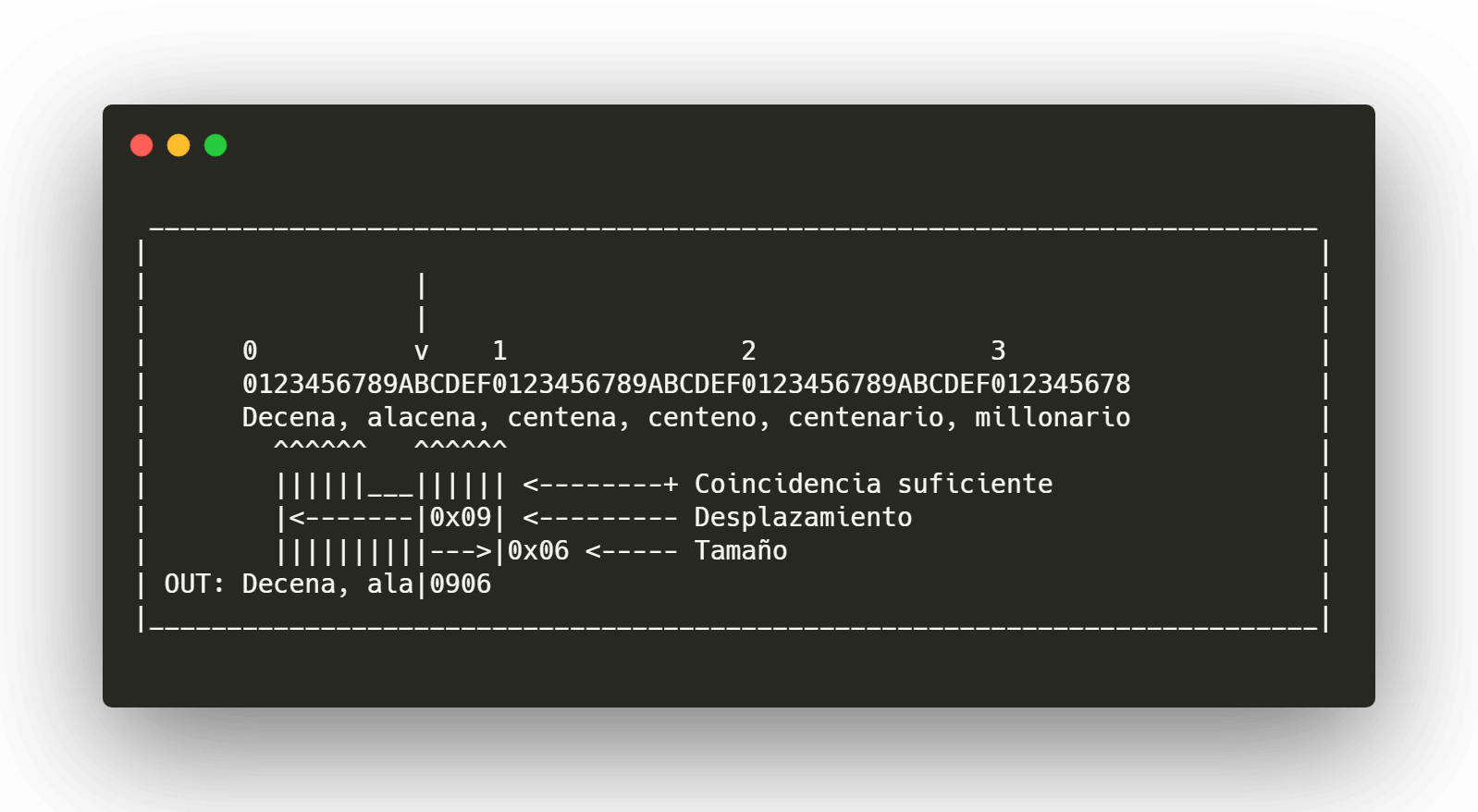
Paso dos
Si encontramos una coincidencia pequeña dentro de los primeros caracteres que no supera el tamaño mínimo, deberemos seguir buscando hacia atrás dentro de la ventana hasta encontrar una coincidencia lo suficientemente grande o bien hasta llegar al límite de la ventana o al inicio de la cadena, en cuyo caso escribiremos los caracteres planos.
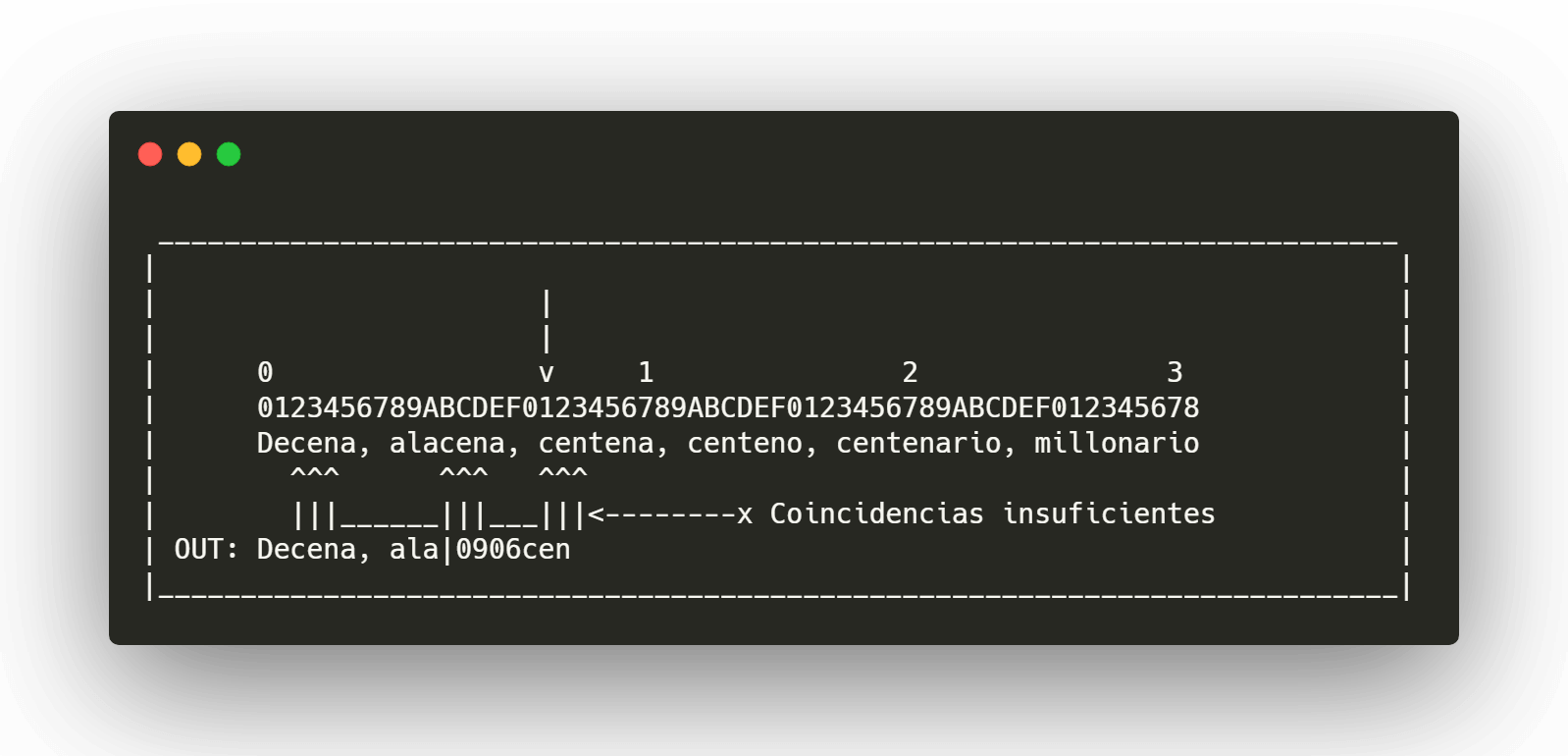
Paso 3
Repetimos el ciclo con el resto de los caracteres.
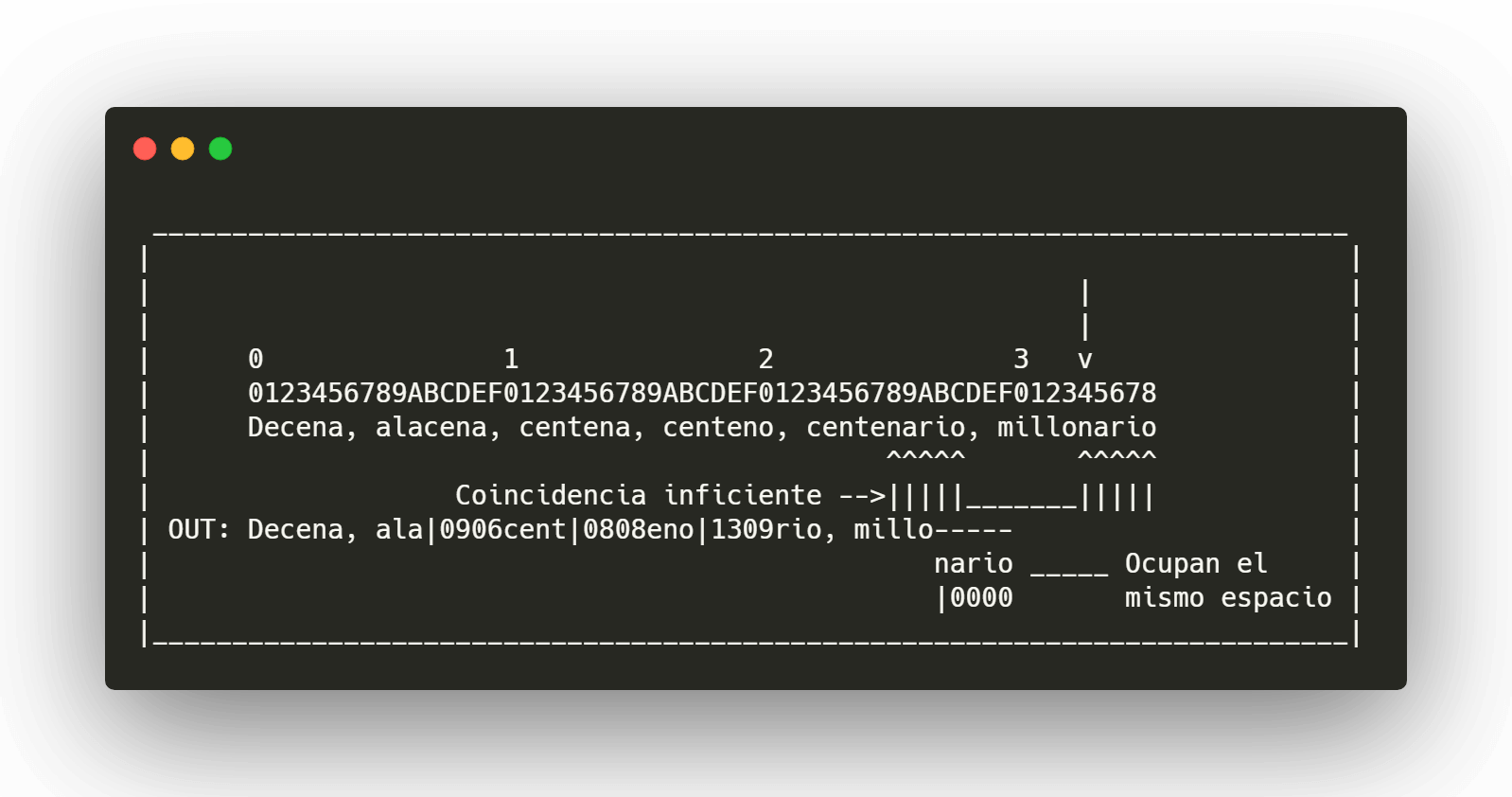
Paso 4
En este caso, el último bloque coincide con uno previamente escrito, por lo que podríamos comprimirlo, el problema es que tiene el mismo tamaño que ocupa el bloque por lo que ahorraremos tiempo de procesamiento almacenándolo sin comprimir debido a que no nos aporta ninguna ventaja.
Resultado final
Terminaremos con la siguiente cadena como resultado del proceso de compresión, esta información será suficiente para reconstruir el texto original.
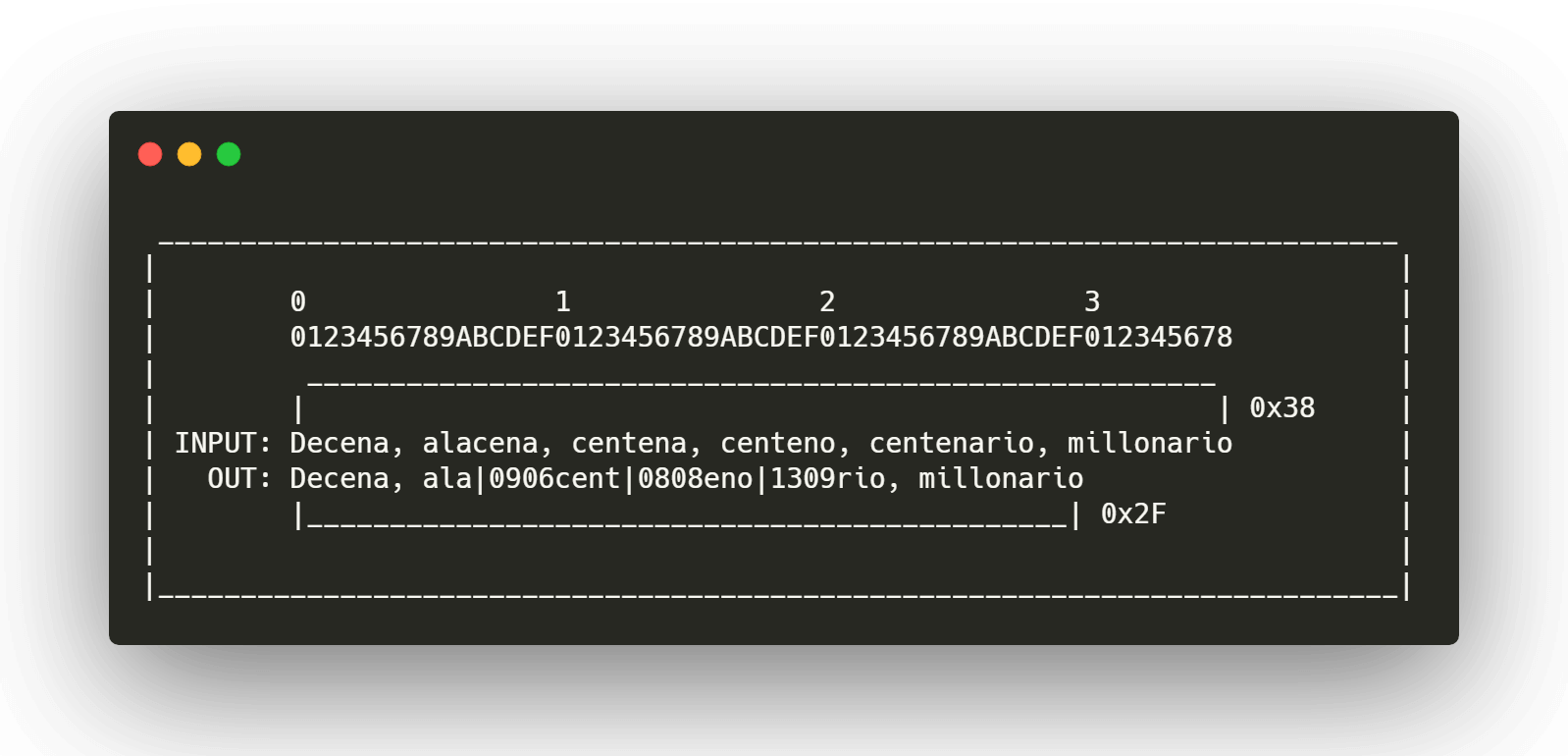
Decena, ala**|0906**cent**|0808**eno**|1309**rio, millonario
Implementación en Go
Vamos a comprimir un archivo de texto que contiene trabalenguas, cada línea la hemos duplicado para contar con suficientes patrones para comprimir.