UUEncode
Repo: https://github.com/umarquez/100DaysOfC0D3/tree/master/14-uuencode
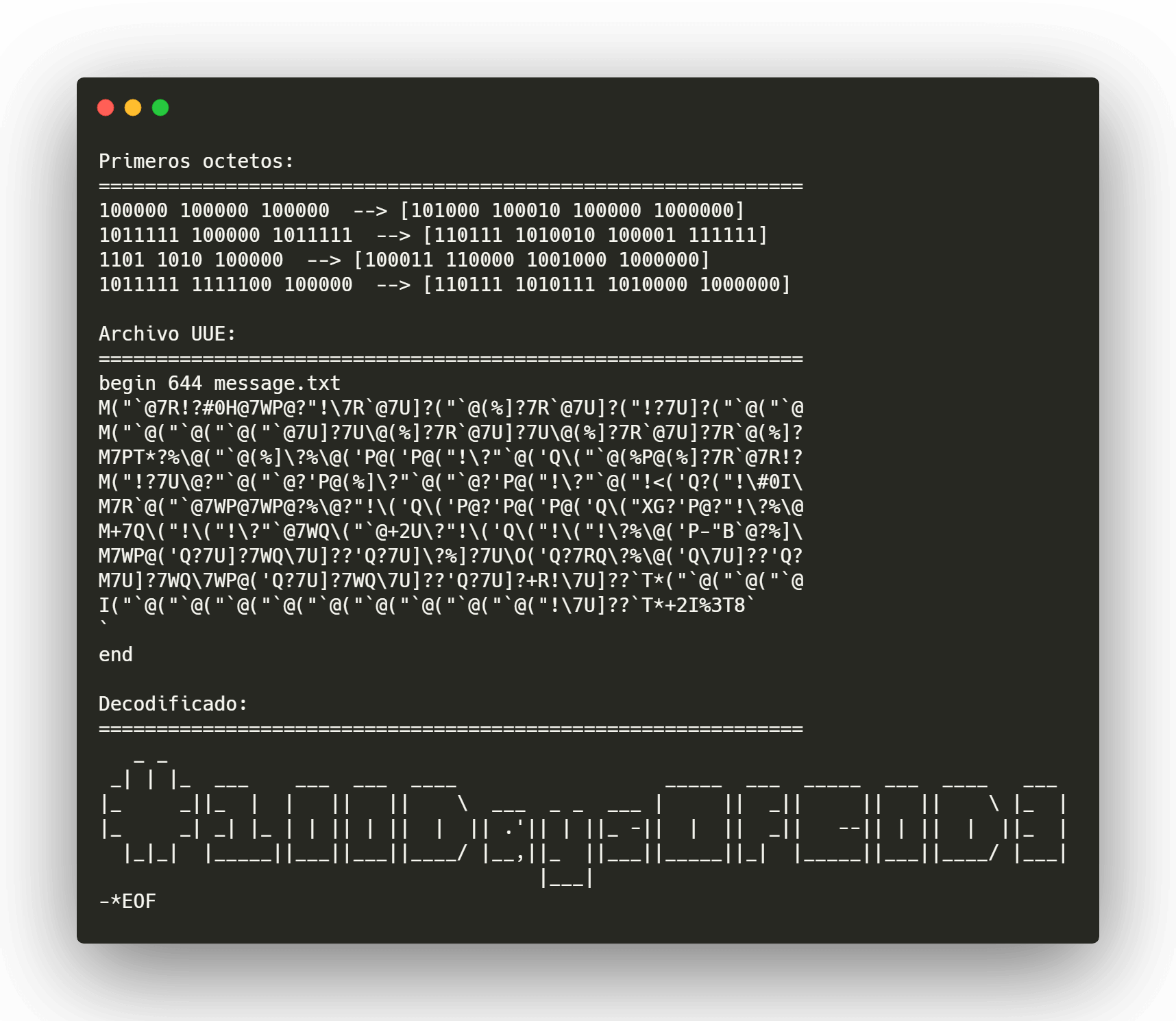
Es un sistema similar al Base64 solo que no utiliza una tabla de caracteres, en su lugar solo suma +32 a cada octeto resultante de la separación en sextetos.
UUEncode proviene de UNIX to Unix Encoding. Se trata de un algoritmo de codificación que transforma código binario en texto. Concretamente, la entrada es un bloque de bytes de 8 bits (generalmente un archivo binario), y la salida un bloque texto de varias líneas con saltos de línea LF o CR-LF y caracteres de texto estándar pertenecientes al alfabeto UUEncode. https://es.wikipedia.org/wiki/UUEncode
Procedimiento
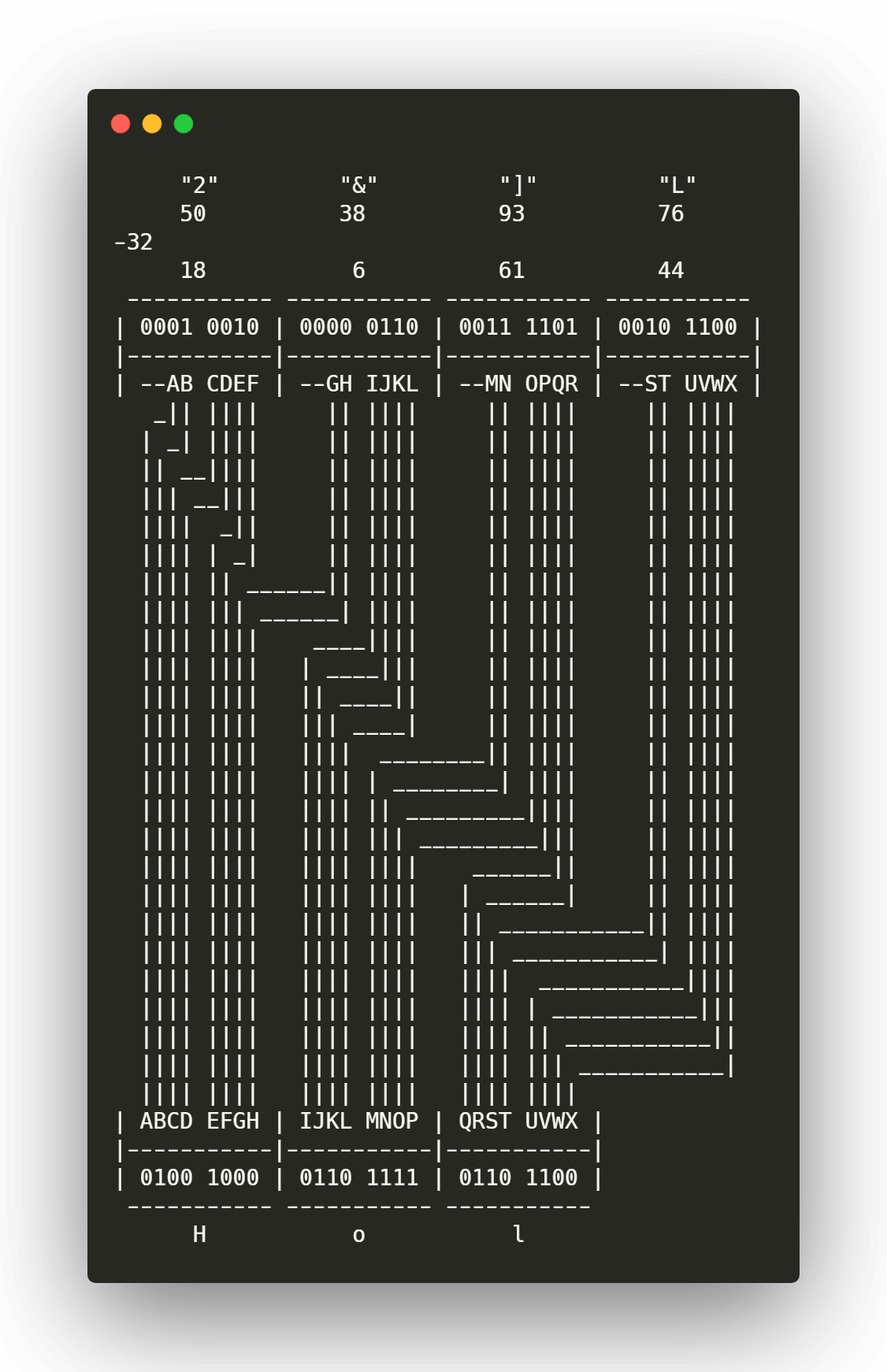
Los pasos para realizar la codificación son los siguientes:
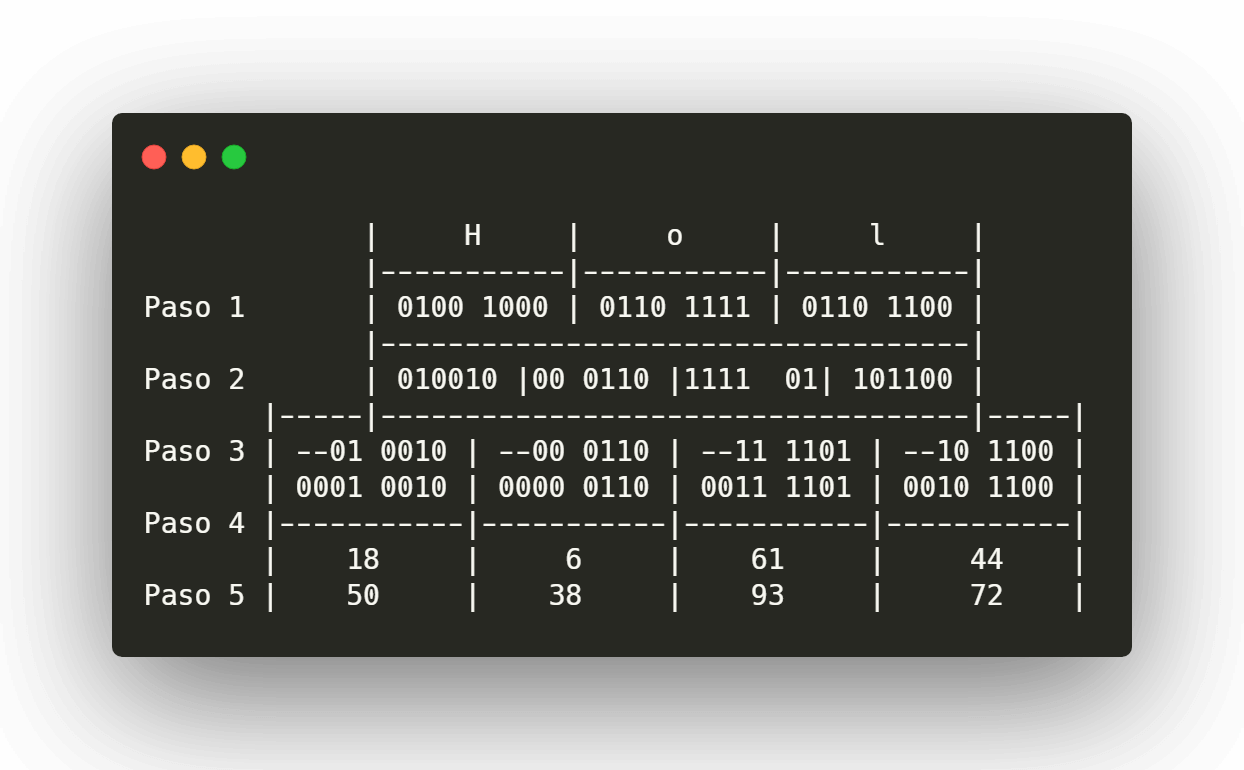
- Convertimos el texto plano a binario
- Obtenemos los bits resultantes en grupos de 6
- Colocamos cada sexteto en los bits menos significativos de cada nuevo octeto.
- Rellenamos los 2 bits más significativos con 00
- Al número resultante sumamos
+32
Una vez realizada la codificación de cada byte, procedemos a separar el total bytes resultantes en grupos de 60, cada grupo será una línea dentro del archivo final a la que deberemos agragar la cantidad de bytes (decodificados) que contiene:
(60 bytes codificados / 4 octetos por bloque) * 3 bytes en cada bloque = 45 bytes del mensaje original_
A esta cantidad sumamos +32 y el resultado lo convertimos en el caracter equivalente, si el contenido fuera lo suficientemente grande la mayoría de las líneas tendrá **60 Bytes** codificados (45 del mensaje original) excepto la última, que podría tener una cantidad menor.
En caso de que la cantidad de bytes resultantes en la línea actual no fuera divisible entre 4, se rellenan los bytes faltantes con espacios.
Finalmente, algunas aplicaciones reemplazan los espacios con acentos ` de tal forma que siempre exista un caracter imprimible, aunque esto es opcional, algunos programas no reconocen los archivos UUE con espacio, por lo que es recomendable reemplazarlos con fines de compatibilidad.
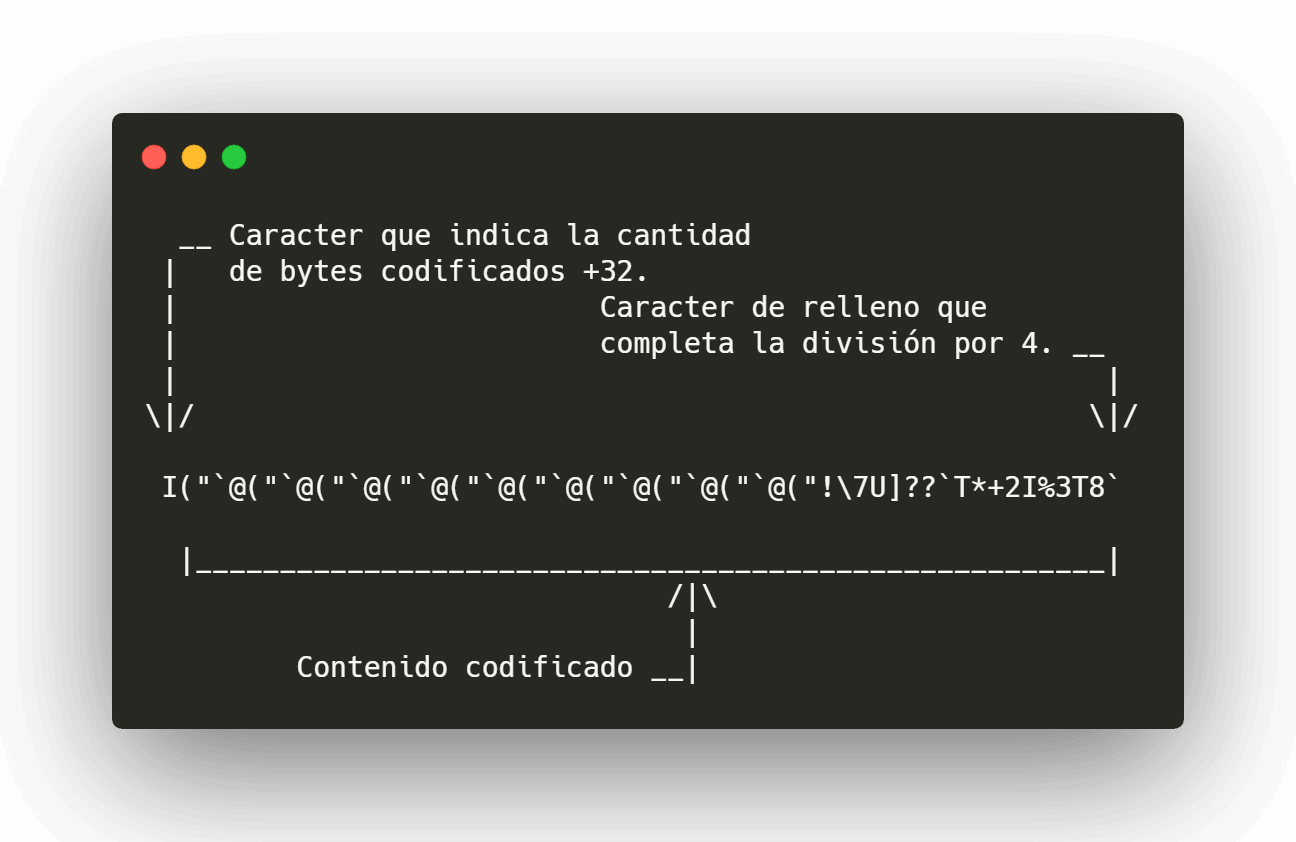 Línea codificada, con los espacios reemplazados por acentos.
Línea codificada, con los espacios reemplazados por acentos.
Este conjunto de lineas debe ser precedido por la cabecera del archivo que contiene el nombre del archivo decodificado y los permisos de este (en caso de que se trate de un sistema unix):
begin <permisos> <archivo>\n
El archivo debe terminar con las siguientes lineas que indican EOF:
`\n
end\n
Reversa
Para realizar el proceso de decodificación, simplemente deberemos tomar cada línea de contenido codificado, restar 32 al primer caracter para obtener la longitud de esta, a continuación vamos decodificando cada caracter restante de la línea, restando 32 para después colocar cada bit en su lugar correspondiente y almacenamos cada octeto resultante en un slice []byte hasta conseguir la longitud de caracteres indicada por el contador inicial.
Este slice resultante lo concatenamos al final del slice que contiene el resultado de las líneas anteriores hasta llegar a la penúltima línea que deberá ser un acento indicando el final.
Implementación en Go